Use Iam Role Upload Data to S3 From Ec2
Secure access to S3 buckets using case profiles
An IAM office is an AWS identity with permission policies that decide what the identity can and cannot exercise in AWS. An instance profile is a container for an IAM office that yous can use to pass the role information to an EC2 instance when the case starts.
In order to access AWS resources securely, you tin launch Databricks clusters with instance profiles that allow you to access your information from Databricks clusters without having to embed your AWS keys in notebooks. This article explains how to gear up instance profiles and use them in Databricks to access S3 buckets deeply.
Note
An alternative to using instance profiles for access to S3 buckets from Databricks clusters is IAM credential passthrough, which passes an individual user's IAM role to Databricks and uses that IAM role to determine admission to data in S3. This allows multiple users with different data access policies to share a Databricks cluster. Case profiles, by contrast, are associated with only one IAM part, which requires that all users of a Databricks cluster share that role and its data access policies. For more than information, see Admission S3 buckets using IAM credential passthrough with Databricks SCIM.
Requirements
-
AWS administrator access to IAM roles and policies in the AWS account of the Databricks deployment and the AWS business relationship of the S3 saucepan.
-
Target S3 saucepan. This bucket must vest to the same AWS account equally the Databricks deployment or there must be a cross-business relationship saucepan policy that allows access to this bucket from the AWS account of the Databricks deployment.
-
If yous intend to enable encryption for the S3 saucepan, yous must add the IAM role every bit a Fundamental User for the KMS key provided in the configuration. Run into Configure KMS encryption for s3a:// paths.
Step 1: Create an case profile to access an S3 saucepan
-
In the AWS console, become to the IAM service.
-
Click the Roles tab in the sidebar.
-
Click Create role.
-
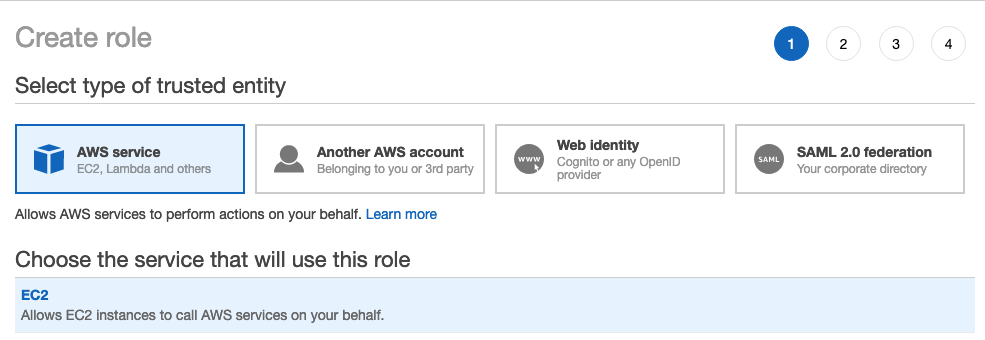
Under Select type of trusted entity, select AWS service.
-
Under Choose the service that will use this part, select EC2.
-
Click Next: Permissions, Next: Tags, and Adjacent: Review.
-
In the Function name field, type a function name.
-
Click Create role. The list of roles displays.
-
-
In the role list, click the part.
-
Add an inline policy to the function. This policy grants access to the S3 bucket.
-
In the Permissions tab, click Add Inline policy.
-
Click the JSON tab.
-
Copy this policy and set
<s3-bucket-proper noun>to the name of your saucepan.{ "Version" : "2012-10-17" , "Argument" : [ { "Effect" : "Allow" , "Action" : [ "s3:ListBucket" ], "Resource" : [ "arn:aws:s3:::<s3-bucket-name>" ] }, { "Effect" : "Let" , "Action" : [ "s3:PutObject" , "s3:GetObject" , "s3:DeleteObject" , "s3:PutObjectAcl" ], "Resource" : [ "arn:aws:s3:::<s3-bucket-proper name>/*" ] } ] }
-
Click Review policy.
-
In the Name field, type a policy name.
-
Click Create policy.
-
-
In the role summary, copy the Case Contour ARN.

Step ii: Create a bucket policy for the target S3 bucket
At a minimum, the S3 policy must include the ListBucket and GetObject actions.
Of import
The s3:PutObjectAcl permission is required if you perform Footstep seven: Update cross-account S3 object ACLs to configure the bucket owner to have access to all of the data in the bucket.

-
Paste in a policy. A sample cantankerous-account saucepan IAM policy could exist the following, replacing
<aws-account-id-databricks>with the AWS account ID where the Databricks environment is deployed,<iam-function-for-s3-access>with the part you created in Step 1, and<s3-saucepan-proper name>with the bucket proper name.{ "Version" : "2012-10-17" , "Statement" : [ { "Sid" : "Example permissions" , "Effect" : "Allow" , "Principal" : { "AWS" : "arn:aws:iam::<aws-account-id-databricks>:role/<iam-role-for-s3-admission>" }, "Action" : [ "s3:GetBucketLocation" , "s3:ListBucket" ], "Resource" : "arn:aws:s3:::<s3-bucket-proper name>" }, { "Effect" : "Allow" , "Principal" : { "AWS" : "arn:aws:iam::<aws-business relationship-id-databricks>:role/<iam-role-for-s3-access>" }, "Activity" : [ "s3:PutObject" , "s3:GetObject" , "s3:DeleteObject" , "s3:PutObjectAcl" ], "Resources" : "arn:aws:s3:::<s3-bucket-name>/*" } ] }
-
Click Save.
Stride three: Note the IAM role used to create the Databricks deployment
This IAM part is the role you used when y'all prepare the Databricks account.
If you are on an E2 account:
-
Equally the account owner or an acount admin, log in to the business relationship panel.
-
Go to Workspaces and click your workspace proper name.
-
In the Credentials box, note the role name at the stop of the Role ARN.
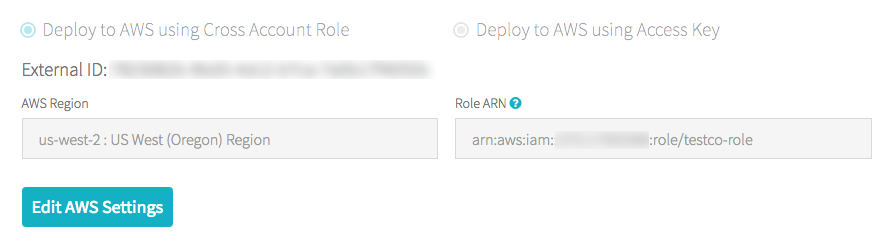
For case, in the Role ARN
arn:aws:iam::123456789123:office/finance-prod, finance-prod is the part proper name.
If you are non on an E2 business relationship:
-
As the business relationship owner, log in to the account console.
-
Click the AWS Account tab.
-
Note the part proper noun at the end of the Role ARN, here testco-role.
Step 4: Add together the S3 IAM role to the EC2 policy
-
In the AWS console, become to the IAM service.
-
Click the Roles tab in the sidebar.
-
Click the role you lot noted in Stride three.
-
On the Permissions tab, click the policy.
-
Click Edit Policy.
-
Modify the policy to permit Databricks to pass the IAM part you lot created in Step i to the EC2 instances for the Spark clusters. Here is an example of what the new policy should look like. Replace
<iam-role-for-s3-admission>with the role y'all created in Step 1:{ "Version" : "2012-x-17" , "Statement" : [ { "Sid" : "Stmt1403287045000" , "Outcome" : "Allow" , "Action" : [ "ec2:AssociateDhcpOptions" , "ec2:AssociateIamInstanceProfile" , "ec2:AssociateRouteTable" , "ec2:AttachInternetGateway" , "ec2:AttachVolume" , "ec2:AuthorizeSecurityGroupEgress" , "ec2:AuthorizeSecurityGroupIngress" , "ec2:CancelSpotInstanceRequests" , "ec2:CreateDhcpOptions" , "ec2:CreateInternetGateway" , "ec2:CreateKeyPair" , "ec2:CreateRoute" , "ec2:CreateSecurityGroup" , "ec2:CreateSubnet" , "ec2:CreateTags" , "ec2:CreateVolume" , "ec2:CreateVpc" , "ec2:CreateVpcPeeringConnection" , "ec2:DeleteInternetGateway" , "ec2:DeleteKeyPair" , "ec2:DeleteRoute" , "ec2:DeleteRouteTable" , "ec2:DeleteSecurityGroup" , "ec2:DeleteSubnet" , "ec2:DeleteTags" , "ec2:DeleteVolume" , "ec2:DeleteVpc" , "ec2:DescribeAvailabilityZones" , "ec2:DescribeIamInstanceProfileAssociations" , "ec2:DescribeInstanceStatus" , "ec2:DescribeInstances" , "ec2:DescribePrefixLists" , "ec2:DescribeReservedInstancesOfferings" , "ec2:DescribeRouteTables" , "ec2:DescribeSecurityGroups" , "ec2:DescribeSpotInstanceRequests" , "ec2:DescribeSpotPriceHistory" , "ec2:DescribeSubnets" , "ec2:DescribeVolumes" , "ec2:DescribeVpcs" , "ec2:DetachInternetGateway" , "ec2:DisassociateIamInstanceProfile" , "ec2:ModifyVpcAttribute" , "ec2:ReplaceIamInstanceProfileAssociation" , "ec2:RequestSpotInstances" , "ec2:RevokeSecurityGroupEgress" , "ec2:RevokeSecurityGroupIngress" , "ec2:RunInstances" , "ec2:TerminateInstances" ], "Resources" : [ "*" ] }, { "Effect" : "Allow" , "Action" : "iam:PassRole" , "Resource" : "arn:aws:iam::<aws-account-id-databricks>:role/<iam-office-for-s3-access>" }, { "Upshot" : "Permit" , "Action" : [ "iam:CreateServiceLinkedRole" , "iam:PutRolePolicy" ], "Resource" : "arn:aws:iam::*:role/aws-service-role/spot.amazonaws.com/AWSServiceRoleForEC2Spot" , "Status" : { "StringLike" : { "iam:AWSServiceName" : "spot.amazonaws.com" } } } ] }
Note
If your account is on the E2 version of the Databricks platform, you lot tin omit
ec2:CreateKeyPairandec2:DeleteKeyPair. If yous are not sure of your account'due south version, contact your Databricks representative. -
Click Review policy.
-
Click Salvage changes.
Step 5: Add the instance profile to Databricks
-
Go to the Admin Console.
-
Click the Instance Profiles tab.
-
Click the Add Instance Profile push button. A dialog appears.
-
Paste in the instance profile ARN from Step ane.
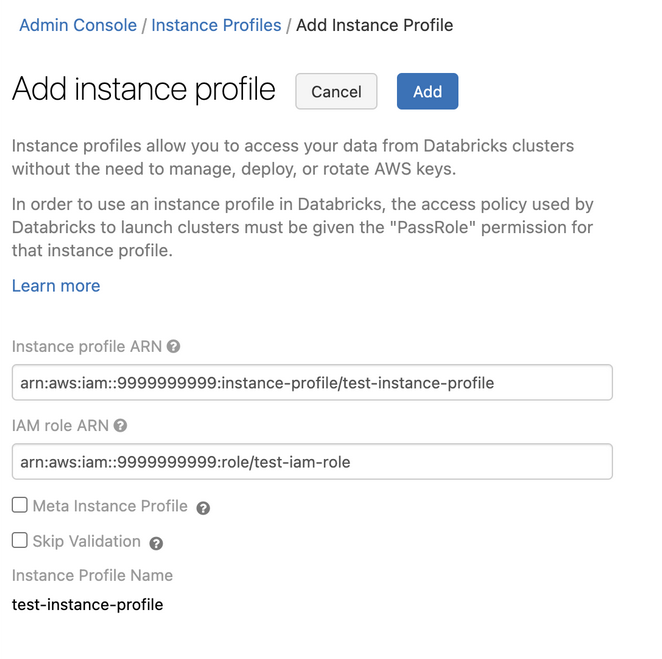
Y'all select the Meta Instance Profile property only when yous are setting up IAM credential passthrough.
Databricks validates that the case profile ARN is both syntactically and semantically correct. To validate semantic correctness, Databricks does a dry out run by launching a cluster with this instance profile. Any failure in this dry run produces a validation fault in the UI. Validation of the instance profile tin fail if the case profile contains the
tag-enforcementpolicy, preventing you lot from adding a legitimate case profile. If the validation fails and yous even so want to add the instance profile, select the Skip Validation checkbox. -
Click Add.
-
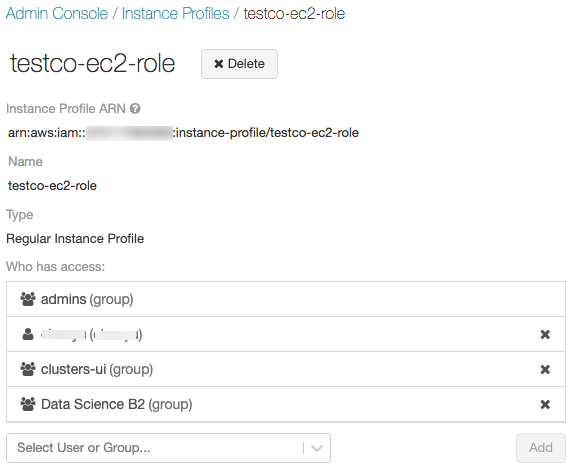
Optionally specify the users who can launch clusters with the instance profile.
Step six: Launch a cluster with the example contour
-
Select or create a cluster.
-
Open the Advanced Options department.
-
On the Instances tab, select the example profile from the Case Profile drop-downward list. This drop-down includes all of the instance profiles that are available for the cluster.
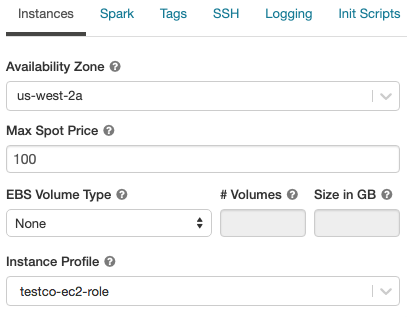
-
Verify that you can admission the S3 bucket, using the post-obit control:
dbutils . fs . ls ( "s3a://<s3-bucket-name>/" )
If the control succeeds, go to Step seven.
Alarm
One time a cluster launches with an case profile, anyone who has attach permission to the cluster can access the underlying resources controlled by this role. To limit unwanted admission, you tin use cluster ACLs to restrict adhere permissions.
Step 7: Update cantankerous-account S3 object ACLs
If y'all are writing to another S3 bucket within the same AWS account, you lot can finish here.
When you write to a file in a cantankerous-business relationship S3 bucket, the default setting allows but you to access that file. The supposition is that you will write files to your own buckets, and this default setting protects your data. To allow the bucket owner to take admission to all of the objects in the bucket, you must add the BucketOwnerFullControl ACL to the objects written by Databricks.
-
On the Spark tab on the cluster item folio, gear up the post-obit backdrop:
spark.hadoop.fs.s3a.acl.default BucketOwnerFullControl -
Verify that you can write data to the S3 bucket, and check that the permissions enable other tools and users to access the contents written by Databricks.
Automated configuration using Terraform
You tin can use Databricks Terraform provider to automatically configure AWS IAM roles and their cluster attachment. Hither'southward a sample relevant configuration, where other resource are omitted for brevity:
resource "aws_iam_role" "data_role" { name = "${var.prefix}-first-ec2s3" clarification = "(${var.prefix}) EC2 Presume Part part for S3 admission" assume_role_policy = data.aws_iam_policy_document.assume_role_for_ec2.json tags = var.tags } resources "aws_iam_instance_profile" "this" { proper name = "${var.prefix}-first-profile" role = aws_iam_role.data_role.proper noun } resource "databricks_instance_profile" "ds" { instance_profile_arn = aws_iam_instance_profile.this.arn } data "databricks_node_type" "smallest" { local_disk = true } information "databricks_spark_version" "latest_lts" { long_term_support = true } resource "databricks_cluster" "shared_autoscaling" { cluster_name = "Shared Autoscaling" spark_version = data.databricks_spark_version.latest_lts.id node_type_id = data.databricks_node_type.smallest.id autotermination_minutes = twenty autoscale { min_workers = 1 max_workers = fifty } aws_attributes { instance_profile_arn = databricks_instance_profile.ds.id } } Ofttimes asked questions (FAQ)
I don't see whatsoever instance profiles configured for my access when I create a cluster.
If you lot are an admin, go to the Admin Console and follow the instructions in this article to add an instance profile. Otherwise, contact your admin, who can add an instance contour using the instructions in this article.
I am using mount points to shop credentials. How do mount points piece of work on clusters with instance profile?
Existing mount points work every bit they do on clusters that don't apply case profile. When you launch a cluster with an instance profile, y'all can too mount an S3 saucepan without passing credentials, using:
dbutils . fs . mount ( "s3a://$ {pathtobucket} " , "/mnt/$ {MountPointName} " ) Source: https://docs.databricks.com/administration-guide/cloud-configurations/aws/instance-profiles.html
0 Response to "Use Iam Role Upload Data to S3 From Ec2"
Post a Comment